
(Credit: Pugo Design Studio)
There is no doubt that online reviews play an important role in our purchasing behavior. From an anecdotal standpoint, I know this because of my own shopping history: If a product has bad reviews online, I keep researching until I find one with favorable reviews.
But it’s also been shown to be true in numerous studies. Research conducted by marketing-software company Moz in 2005 estimated that 67 percent of consumers are influenced by online reviews.
But relying on online reviews prior to making a purchase is not a new trend. Rather, it’s an old concept that is manifesting itself in a new medium.
Why is that?
Social Proof
As described in his book Influence: The Psychology of Persuasion, Robert Cialdini describes social proof this way: “One means we use to find out what is correct is to find out what other people think is correct.”
Or, as Chris Campbell writes in Entrepreneur, “Science describes social proof as a psychological phenomenon in which people follow the actions of others in an effort to reflect what is considered correct behavior for any given situation — including online experiences. Simply put, social proof influences people’s decisions on how they should behave.”
Social proof and online reviews have definitely shaped our purchasing habits, and the owner/leader of any business can be put at a significant disadvantage if they haven’t yet figured that out.
When it comes to online review sites, the concept of social proof tells us that we are more likely to make a purchase from a business if the reviews are good, since we are relying on the partiality of others.
Developing the Informal Study
I’m a scientist by nature, so when I get an idea in my craw, I like to test my theory. In this case, I set out to determine the key terms, used by people who have visited and reviewed a single restaurant, that resulted in a good review. I assumed that someone who left a good review generally had a positive experience.
With this information, I theorized, it is then possible to reverse-engineer marketing materials in a way to increase the probability of a higher-star review on Yelp, thereby increasing social proof and attraction to the restaurant.
For this project, I followed a general approach to reach the objective that is described:
- Obtaining the data
- Understanding/pre-processing the data
- Training a classifier on the data
- Interpreting results
Before going into the details and results of this project, I want to run down the different tech tools I used:
- Jupyter Notebook with Python 3.5 for all of the computations
- Pandas to facilitate the data processing and manipulation of the data set
- BeautifulSoup to data-scrape the Yelp website
- xlsxwriter to write the scraped data to an archivable file
- Scikit-learn to train a model that would be able to determine the results
Step 1: Obtaining the Data
For this project, I opted to data scrape the Yelp website to get the information I needed. Being a scientist, I’ve always been interested in the concept of data scraping, as it’s a highly iterative and analytical process that requires a thorough review of the way the data is formatted in order to write a script, or short computer code written to perform an automated task.
The resulting script is also very fragile since websites can change the structure and format of their code at any time. This means that a script that works on one day may not work the next because the site’s coding has changed.
So regardless of what tool you use to data scrape a website, the first step in any scraping project is to analyze the site’s HTML to look for structure, patterns, and/or any other details that can be used to get the information that you need.
For this project, I needed a way to get both the text of each review as well as the number of stars left by the reviewer.
So I took a gander at the Yelp code and made note of the following.
Number of reviews per page and the URL pattern
On the Yelp page, the first thing that jumped out at me was that, for restaurants with numerous reviews, only 20 reviews were shown per page. And when I advanced to the next twenty reviews, the URL of the page would change to include a “20.” For example, the second page of reviews for Monkey House Cafe has this URL:
https://www.yelp.com/biz/monkey-house-cafe-huntington-beach?start=20
The URL pattern ultimately allowed me to build a list of URLs that would allow me to access all pages for a single restaurant on Yelp. For example:
https://www.yelp.com/biz/monkey-house-cafe-huntington-beach
https://www.yelp.com/biz/monkey-house-cafe-huntington-beach?start=20
https://www.yelp.com/biz/monkey-house-cafe-huntington-beach?start=40
https://www.yelp.com/biz/monkey-house-cafe-huntington-beach?start=60
https://www.yelp.com/biz/monkey-house-cafe-huntington-beach?start=80
Use of commas and potential problems when building a CSV file
Since this project used natural language processing, I knew it would be common to see commas within the text of the reviews. This posed a problem since commas are often used within data sets to separate fields. In fact, one of the most common file formats for saving data is called CSV, which stands for “comma-separated values.” So instead, I decided to export all of the data into a good ol’ standard Excel sheet to get around the comma issue.
Here’s a link to the GitHub repository with the iPython notebook used to get the data.
Step 2: Understanding/Pre-Processing of the Data
I noticed that, compared to the average Yelp restaurant listing, the one I’d chosen had a decent number of Yelp stars. In thinking more about it, this was a red flag since I knew that the data set would be made of reviews that had higher amounts of stars. Nonetheless, I still decided to pursue the use of this data set.
I also thought about combining reviews from a few more restaurants with a lower average, to even things out, but I decided against it since I wanted this analysis to be specific to what people are saying about this restaurant in particular.
Originally, when I started out on this project, the intent was to determine the words that are most predictive of a one- or five-star review, which means I wouldn’t have to analyze two-, three- and four-star reviews. However, I soon realized that discarding those mid-range reviews from my data set of 276 overall would leave me with a scant 120 reviews. As a scientist, I wanted a larger data set to ensure my results were as accurate as possible.
And so I decided to change the objective of the project to the following:
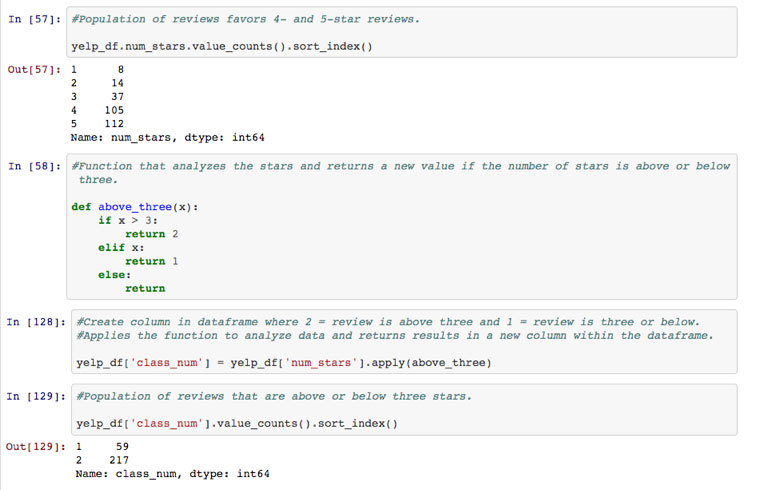
Determine the words used by reviewers that lead to the assignment of a four-star or higher review versus a three-start and lower review. To do this, I reassigned each review as being part of one of two categories:
- Class 1: three-star or lower
- Class 2: four-or five-star review
I then assigned each review to one of these two classes using a conditional statement (i.e., if-statement).
Step 3: Training a Classifier on the Data
I used the data I scraped from the Yelp website to train a classifier, in this case, a multinomial naive Bayes model. (If you want to learn more about naive Bayes models, check out these videos on how a computer can learn to do well on an exam and a short and simple example of naive Bayes calculations.)
I decided to train a classifier with the data because I needed a way to determine the distribution of each word (token) within each class. For example, how many times did the word “delicious” appear in Class 2 reviews versus in Class 1? It is these counts that I wanted to use to determine how a single word can influence the class of a single review.
In reading the scikit-learn documentation, these values are available as the feature_count_ attribute within the naive Bayes model object. I used this attribute to determine the distribution of each token in a given class (either Class 1 or 2).
I then took the ratio between each group to get a ratio of how strong a single token was in influencing a classification into Class 1 or 2 within a pandas data frame. When taking the ratio, I added a 1 to each column to eliminate any possibility of dividing by zero.
I then sorted the data in both ascending and descending order to find the top 10 words that could influence a review having four or more stars or three or fewer stars.
Step 4: Interpreting Results
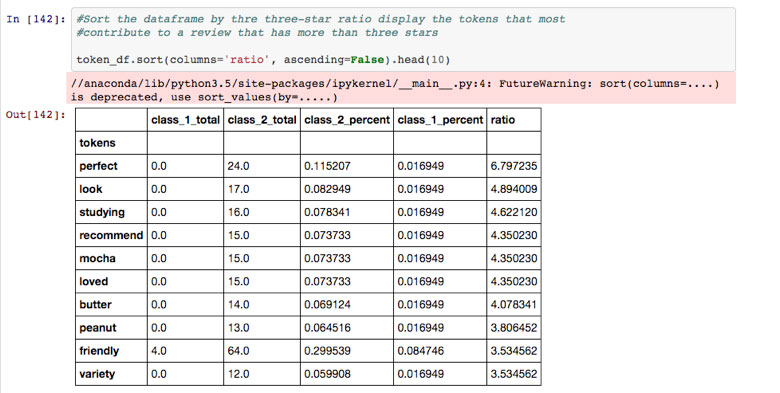
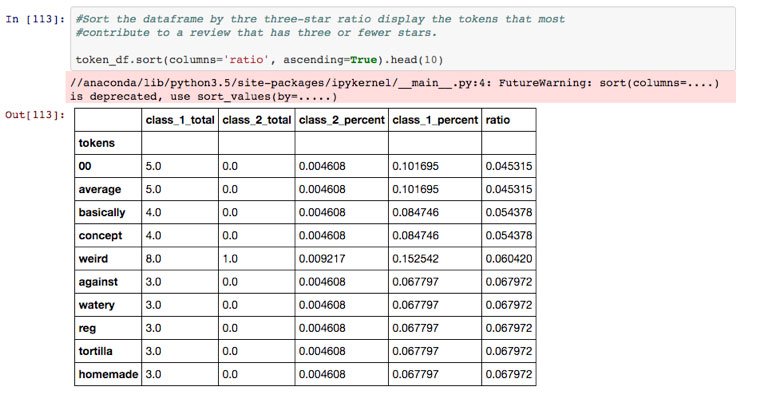
By using the attributes from the naive Bayes classifier, I was able to get the top 10 words (tokens) that are most commonly found in both Class 1 and Class 2 reviews. Here are the results:
Top 10 Words Found in a Four- or Five-Star Review
Top 10 Words Found in a Three-, Two- or One-Star Review
Discussion
The objective of this project was to determine the words used by people that were most likely to give a restaurant a four- or five-star review versus one that was three-star and below.
In hindsight, if I were to repeat this study for another restaurant, I’d make sure to choose one with a larger data set larger (1,000 reviews) and more balanced (i.e., each review has an average number of star ratings of 2-3).
The point of all this data scraping and manipulation was to learn what word or words people were using when leaving a “good review” so that I could then “reverse engineer” the marketing copy in a way that would encourage people to leave even more good reviews.
For example, in this project, I noticed that the word “studying” was common in Monkey House Cafe reviews that had a star rating of more than three. Therefore, one recommendation would be to encourage people to come to the cafe to study so that more people would write that as the reason they had visited the restaurant:
Copy: Looking for the perfect place to study?
Once the reviewer sees such an ad and goes to the cafe to study, if they have a good time, then a probable review would contain language such as “Came to this place to study…”
Now, if the reviewer’s experience was awesome, then we also know that there would be a high chance the reviewer would leave a four- or five-star review.
Future work for this project can include the analysis of multiple-word phrases (e.g., “perfect studying,” to combine two of the top-10 tokens) to determine what phrases are used when providing a four- or five-star review. However, for that to work properly, I’d need the larger data set I mentioned earlier.
Check out the GitHub repo with all of the code used in this project.